Michael Wu on TechCrunch touches upon what I have long thought is the fundamental problem with attempts to measure someone’s influence in social networks.
One of the reasons that brands don’t understand digital influence is
because they don’t seem to realize that no one actually has any
measured “data” on influence (i.e. explicit data that says precisely
who actually influenced who, when, where, how, etc.). All influence
scores are computed from users’ social activity data based on some
models and algorithms of how influence works. However, anyone can
create these models and algorithms. So who is right? How can we be
sure your influence score is correct?
Influence is not measured directly, it is measured through other variables (likes, retweets, etc.) that stand proxy for influence. So instead of this 



But this is not easy to do when the thing that you are trying to measure and predict is something that people care about and can influence by altering their behavior.
As we learn from the behavior economics of humans, when we put a score
on something, we create an incentive for some people to get a better
score. This is human nature. Because people care about themselves,
they care about any comparisons that concern them, whether it is their
websites, cars, homes, their work, or just themselves. Some would go
so far as to cheat the algorithm just to get a better score. In fact,
Google’s PageRank algorithm has created an entire industry (i.e. SEO)
around gaming their score.
It’s not so hard to “cheat the algorithm”. Influence scores that include variables that you control directly (how many posts you make, for example) can be gamed by simply changing your own behavior. But even influence models that carefully avoid such variables by only including variables that represent what other people think of your behavior can be cheated.
Reciprocity is one way that this is done. Bob tweeted something you couldn’t care less about, but by retweeting Bob you’re helping to nudge up his influence score (on Klout, say), and you do that because Bob is the kind of guy who rewards retweets with retweets (or follows with follows, likes with likes, etc).
Suppose that an influence model 
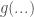
One way that an influence modeler could hedge this reciprocity attack on his model would be to measure, for every retweet, the length of the shortest retweet cycle. If you retweet Bob and he retweets you, the cycle is length 1. If you retweet Bob, Bob retweets Alice, and Alice retweets you, the cycle is 2. The idea is that the longer a cycle is the more likely it is evidence of genuine influence; very short cycles smell like reciprocity.
The problem with this approach is that it makes the concept of influence look like an asymmetrical relationship: if you influence Bob, Bob cannot influence you, otherwise it’s classified as reciprocity. But a key stylized fact of social networks is that they are mostly made up of groups of people who identify with one another, and sometimes the group is self-contained.. there is no path to a node outside the group. Nobody would be happy with construing the concept of influence in such a way that it can’t apply locally, with people in the group influencing each other.
Did you retweet/like/comment Bob because he influenced you or did you do it in anticipation of his reciprocity? The intention seems inscrutable from data on social network graph alone.
Measuring influence is hard, and it is especially hard when people have an incentive to manipulate the measurement of it. Personally, I think this is just an instance of a larger problem all over the internet. It’s just so damn hard to find signal in data that is costless to generate. There is no cap on the number of tweets you can make, the number of likes you click, the number of posts you make, and so on. If there were some external friction placed on these activities so that people had to ration them, the tide of noise would recede and bring more signal into view.
So here’s an idea: make every tweet cost three minutes of CPU time, during which your machine runs some computations for a socially useful distributed computing project (climate prediction, genome sequencing, alien searching.. you choose). The friction caused by this would not only cause people to ration their social networking, greatly improving the signal-to-noise ratio, but the friction itself would benefit society. Who could complain (except the spoofers)?

Few tentative observations:
1/ ‘influence’ is a very deep concept – what makes you think you can measure it? it seems like the importance of ‘influence’ depends on a. who is being influenced b. in which way .c. when d. with which consequences. and more. I personally find the concept of trying to measure influence a non-starter, all you are going to end up with are proxies.
2/ the opportunity for gaming influence scores is apparent. So is the benefit of creating and belonging to digital cultures in which every member promote one another’s content .. that makes the whole ‘influencer’ game impossible unless you have a model of which nodes can be expected collude and which not (see the ripple project ‘Unique Node List’ for an attempt at dealing in with a similar threat in a different context). Algorithms in this space need to be intelligent, but the intelligence needs to be social?
3/ your suggestion re proof-of-work on tweets, yes that would help, but still does not include any weighting relating to who is influenced. If you influence a ‘nobody’ it should count for less than if you influence a ‘somebody’?
Perhaps more to point – what fraction of twitter users (for example) care about validated measures of influence? If you make people “pay” they likely won’t bother at all. So now you have an influence score of people willing to “pay” to have their influence standing validated. Of what use is that to anybody who actually care about influence for real world reasons (like directing marketing or political communications?)