David Andolfatto, Vice President of the St Louis Fed, published a most interesting post yesterday Fedcoin: On the Desirability of a Government Cryptocurrency. Andolfatto’s post is itself in reference to JP Koning’s Fedcoin piece of last October. Back then, I wrote a bit about that on a private email list that is usually devoted to topics relating to blockchain protocol design. I thought the Fedcoin thought experiment was interesting fodder for our monetary intuitions. Still do. So here it goes.
A central bank backed blockchain payments network for a national currency like the USD is a neat idea. It would, first of all, put digital cash on the map for good. And digital cash that trades at parity with an economy’s well-established unit of account is a far more useful medium of exchange than a volatile cryptocurrency like bitcoin. Andolfatto:
And so, here is where the idea of Fedcoin comes in. Imagine that the Fed, as the core developer, makes available an open-source Bitcoin-like protocol (suitably modified) called Fedcoin. The key point is this: the Fed is in the unique position to credibly fix the exchange rate between Fedcoin and the USD (the exchange rate could be anything, but let’s assume par).
So the idea is that the supply of Fedcoin expands and contracts perfectly with changes in Fedcoin demand, as the Fed would issue and redeem Fedcoins for USD deposits at parity.
Exactly what sort of blockchain protocol would be appropriate for this scheme is an open question. It certainly cannot be a proof-of-work protocol. Maybe it wouldn’t be a blockchain protocol at all. This is what I wrote about the idea on that email list:
forget nakomoto-consensus for a moment and assume Fedcoin is just a 1990’s implementation of digital cash, Fed-run servers, chaumian blinding, etc. Assume it’s executed well, so we’ve got something with all the properties of cash with the added benefit of cheap electronic payments. That’s actually a pretty evocative idea on its own, even though we had everything in place to do it 20 years ago and it has nothing to do with blockchains.
So what’s innovative about Fedcoin–whatever its technical implementation may be–isn’t blockchain tech. It’s rather the monetary implications of central bank sponsored digital cash. And those implications are IMO more profound than what both Koning and Andolfatto suggest. Andolfatto says:
Of course, just because Fedcoin is feasible does not mean it is desirable. First, from the perspective of the Fed, because Fedcoin can be viewed as just another denomination of currency, its existence in no way inhibits the conduct of monetary policy (which is concerned with managing the total supply of money and not its composition). In fact, Fedcoin gives the Fed an added tool: the ability to conveniently pay interest on currency.
In his theoretical work, Andolfatto has advocated the interest-bearing money concept as a way of increasing the efficiency of money holdings: the economic efficiency of the Friedman rule without the deflationary implications. So I can see why Andolfatto is interested in digital cash.
Indeed, Fedcoin could pay interest (at the IOER rate?). In fact, if Fedcoin were to displace the use of greenbacks, this could remove the last remaining impediment to negative nominal interest rates, so perhaps that is one aspect of Fedcoin that would actually expand rather than inhibit the conduct of monetary policy.
Just another dollar denomination?
But I think that Andolfatto and Koning are seriously underestimating the implications of Fedcoin. This is what I wrote:
But I’m not interested blockchains here, it’s the economic implications, which are radical: it would cause the demise of fractional reserve banking. A central bank that went down this path would effectively bring about something dubbed the “Chicago Plan“, an early 20th century proposal that banks hold 100% reserves and the CB compensate for the destruction of privately-created “endogenous money” with a dramatic expansion of base money (monetising in a non-inflationary way much of the national debt as a side-effect).
So the problem (or opportunity, depending upon your perspective) with Fedcoin is that it will compete with bank deposits in a big way. Unlike your bank deposit, which is an unsecured loan to a highly leveraged deposit-taking institution, Fedcoin is central bank money. It cannot default, by definition. Fedcoin would be better than credit than US Treasury Bills. Why would anyone use bank depo (and it’s creaky array of payment systems like ACH and SWIFT) given such an alternative?
The only reason why we are accustomed to thinking that cash and bank deposits are the same thing, exchangeable 1-for-1, is because for 80-odd years bank depo has been buttressed by the central bank’s Lender-of-Last-Resort (LLR) facilities, government-backed deposit insurance, and a bank debt credit market built around expectations that banks are Too-Big-To-Fail (TBTF).
Fedcoin would be immensely popular. Not just among individuals, but institutions, which could finally own large balances of the unit-of-account without having to assume the credit risk of a >30x leveraged balance sheet with a big duration miss-match between its assets and liabilities.
In no way inhibits the conduct of monetary policy?
Paper cash is central bank money too. But without an electronic payment rail, it’s usefulness is capped. But digital cash with a central bank issuer… that’s useful for everything except black market trade. It’s hard to see how the Fed could both maintain the parity peg and not see the “Fedcoin” line-item on its balance sheet swell. Banks would have to offer depositors a credit spread over the “Fedcoin rate” to prevent a run.
So, the introduction of Fedcoin would place the Fed in a dilemma. If it rations the supply of Fedcoin, Fedcoin will trade at a premium to bank depo and the peg breaks on a spot basis. But if you make banks compete with the Fedcoin rate for bank deposits and enforce parity (you can depo/withdrawal Fedcoin at your bank 1:1), then the Fedcoin rate is going to be determined more by the demand for Fedcoin relative to bank depo than macroeconomic considerations and, anyway, the peg breaks on a forward basis.
Why don’t you have an account with the Fed?
When you think about it, it’s rather odd: why can’t you have an account at the Fed? Why must you assume the credit risk of a bank just in order to transfer dollars electronically? (That’s a question that really should be asked more frequently.) The reason why Fedcoin is so radical is that, for the first time, central bank money would be available to everyone in electronic form. Electronic payments would finally be divorced from bank deposit.
Who said payment systems were boring! The whole edifice of fractional reserve banking is held up by the union of electronic payments and bank deposit (along with LLR, depo insurance, etc). Break that union and, I conjecture, the union of fiat money and fractional reserve breaks too.
Which may be no bad thing. Why must fiat money be inextricably linked up with credit? Without fractional reserve banking, the locus of credit origination could be what it should be: the issuance of a debt instrument with a market price, rather than bank loan financed with a privileged, publicly-subsidised debt instrument (bank deposit) that doubles as the electronic medium of exchange.
The other Friedman rule
So, if you accept my thesis that Fedcoin will undermine fractional reserve banking, it makes allot of sense to wonder what sort of monetary policy the Fed should conduct in a world where the money supply is equal to the monetary base. I’m going to step out on a limb here and say that discretion goes out the window and policy is run by rules.
And rules can be programmed. Milton Friedman famously once said that the FOMC could be replaced by a computer. I would like to go further and say that it should be replace by a distributed computer.
So my kinda Fedcoin wouldn’t be a fixed exchange rate regime with Fedcoins exchangeable with Fed deposits at parity, leaving the existing monetary policy instruments and discretionary policy framework intact. Instead, the liabilities of the Fed’s balance sheet would be entirely denominated in Fedcoin. Monetary policy would be an algorithm embodied in a DAO, and the FOMC could only change the algorithm infrequently, if at all.
Whether the monetary policy algorithm is Friedman’s k-rule, a Taylor Rule, Fisher-like dollar stabilisation, or whatever, the idea is that of a monetary policy represented by rules, the execution of which not even the FOMC could manipulate outside of the “meta rules” encoded in the FOMC DAO.
Cypherpunk monetarism
And Fedcoin along these lines is intriguingly close to the budding research around stable cryptocurrency. There are differences. The stable coin ideal is still very much a cryptocurrency vision, built around permissionless p2p networks autonomous of any off-chain institutional governance. My seigniorage shares model, for example, attempts to bootstrap the functionality of a central bank balance sheet using an on-chain digital asset that is distinct from the coin used as medium-of-exchange.
But an institutional model like Fedcoin would have an easier time of it. So my kinda Fedcoin: a stablecoin blockchain, combined with an off-chain balance sheet and some policing of the consensus protocol and data feeds. Not so different from “cypherpunk monetarism”.
 be some future time when the growth rate of transaction volume
be some future time when the growth rate of transaction volume 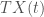 levels out and let
levels out and let 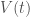 be the velocity at time
be the velocity at time 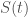 is the supply of bitcoin:
is the supply of bitcoin: 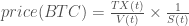
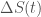 is a function of
is a function of 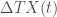 , or a function of the exchange rate itself. This can be done in an entirely trustless way, and such a coin is likely to have a much more stable exchange rate and be a better medium-of-exchange.
, or a function of the exchange rate itself. This can be done in an entirely trustless way, and such a coin is likely to have a much more stable exchange rate and be a better medium-of-exchange.